InversionNet: An Efficient and Accurate Data-Driven Full Waveform Inversion
InversionNet: An Efficient and Accurate Data-Driven Full Waveform Inversion
传统的FWI很贵且效率不高,本文提出了一种深度学习反演方法,利用神经网络(CNN)学习和预测地震速度和地下结构的关系构建地震速度模型。
背景
物理驱动技术
时域中的声波方程为
其中是位置向量,代表密度,是体积模量,代表震源,为压力波场,为时间。正演表示为
其中代表波场位移,代表正演操作,代表速度模型向量(密度和波速)。使用时域交错网格有限差分来求解。同时本文只关注恒定密度+弹性介质的情况。
对于反演,便可以看成一个优化问题,最小化目标函数
其中代表真实记录的数据,代表正演结果,代表L2范式,是正则化惩罚参数,为正则项,常用Tikhonov正则项(总方差正则化、岭回归、TV)
其中为高通滤波矩阵或单位矩阵。TV正则项为L2正则项,非常适合平滑模型。
最终添加TV正则项的目标函数为
其中在2维模型中正则项为
其中代表网格点处的方向导数。
后面还介绍了对于正则化参数的大小分析,以及MTV正则化技术,并且指出FWI基于梯度优化方案,成本高且对于小型结构的分辨率不够好。
数据驱动技术
- 这便是本文的重点,直接从数据中得到速度模型而不是基于物理方法。和传统FWI的不同就是这种方法需要大量的数据训练模型来保证预测的准确性。
方法
FWI中的正演模型可以简单表示为
其中是传播算子,是地质模型,是地震数据。本文的数据驱动方法便是通过CNN近似拟合了,再通过局部链接CRF进一步细化输出。
因为目标是将数据从一个域转移到另一个域,本文将CNN设计成编码-解码架构。编码器用于提取数据中的高级特征并降低数据维度。解码器用于将这些特征转换到其他域上,具体架构如图1所示。
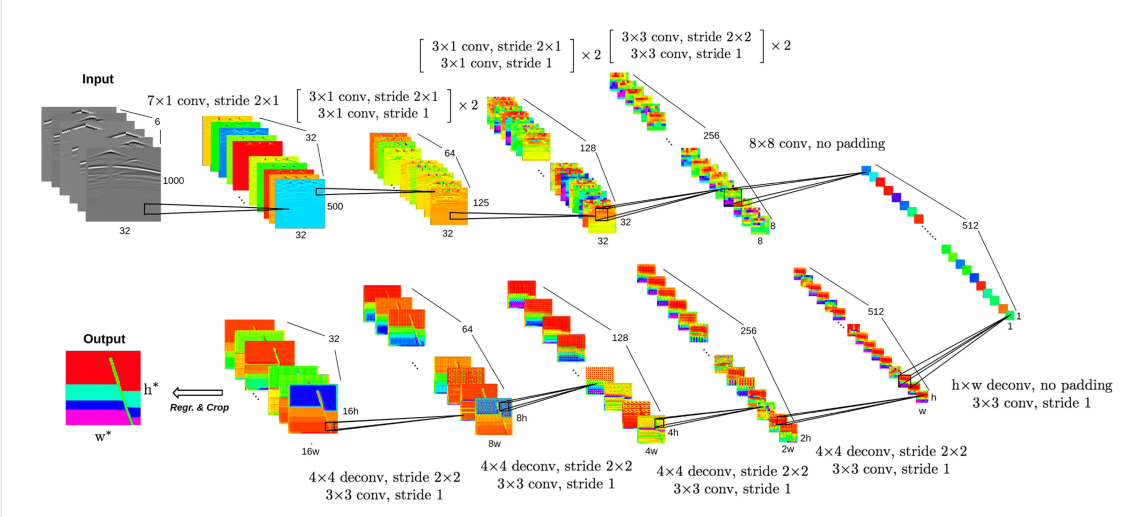
图1. CNN网络架构 可以看到这里的编码器用了四层卷积把变成在变为一维张量。解码器再进行上采样变回指定尺寸。
编码器
编码器中包括一组卷积块,每块可以表示为
其中为卷积核,代表步长。为归一化操作
其中为特征图的平均值和方差(用一个小批次计算),是一个小常数。
解码器
解码器包含多种卷积和反卷积操作进行上采样,这里使用的卷积核进行反卷积将分辨率提高一倍,再使用的卷积核进行卷积细化上采样的特征图。最终使用L1损失函数计算误差
其中为真实数据,为模型预测数据。
条件随机场
条件随机场(Conditional Random Fields,CRF)是用来细化模型精度的技术。L1损失训练的CNN不能对每个位置之间的相互关联进行建模,所以不能完全捕捉速度模型的结构特征,为了更好的反映地质结构,本文构建了一个局部链接的CRF用于进一步精细化。
CRF由Gibbs分布定义为
其中为变量,为定义在上的一组团(clique)为的图,每个团的势(pontential)为。代表对所有势求和的能量函数,为归一化常数。
CRF的参数将使用最大化后验(MAP)进行优化
将遍历尺寸为的所有速度模型,遍历所有可能速度值。速度值以隐式条件地包含于每个速度模型中。CRF的能量函数由一个一元势函数和一个成对势函数组成:
其中为与相连的节点集合。一元势函数对输入和每个独立输出建立映射关系。成对势函数对输出与两两建立联系。定义如下
其中为CNN输出的速度预测值,为学习权重,为相似矩阵,有
其中为解码器生成的最终特征图的特征向量,为位置向量,为超参数(hypeparameters,指人工调节的参数)。简单的说便是两个不同的节点如果特征、位置近似的话就越大,从而势函数值越大。
CRF中与负相关,即越小越好,预测的位置越准确一元势越小,且两个相似节点的预测也相近的话则成对势也越小,则越小。而如果相邻节点预测值不同则惩罚将变大即变大。
近似推导
具体计算的时候不会直接式13、式16求解,因为涉及求大矩阵的逆,复杂度为。所以一般使用均值场理论(MFT)来计算分布,满足,且和之间KL散度最小。此时有
其中为分布在下的期望。
联立式13、式16、式17、式18和式20有
由于是关于的二次函数,所以它可以被高斯分布表示
由于,所以这里令使得为有效分布。最后使用式22、式23迭代计算直到满足收敛准则为止,其中使用单次预测值作为的初始值。
最后对每个因子分布执行MAP得到,有
训练
这里的目标是找到参数使得最大化,通过上述的近似推导得到损失函数为
通过投影梯度上升法得到的递推公式为
其中为学习率,为0。
总结
- 一种端到端的编码器-解码器架构。
- 输入的地震数据高宽比过大,优先压缩高度,不过这导致丢失时空相关性。
- 引入CRF理论优化网络,使用MFT进行实际计算。