数值分析
数值分析
- 2024研究生课程「数值分析」笔记&复习要点。
1. 绪论
1.1. 误差和误差限
绝对误差
即真实值和近似值的绝对差,一般情况我们不知道真实值,所以求不出绝对误差。但是可以求绝对误差限。
相对误差
相对误差限为。
1.2. 有效数字
若,且,则有位有效数值。
这里说人话就是把数先变成科学计数法,然后再看,就是有效位数。
例如作为近似时的有效数字:
且,所以得,即有位有效数字。
若有位误差,则的相对误差限满足
数值计算
- 不要扩大误差,例如迭代解乘上常数改为。
- 不要近似数减法,一般做有理化处理。
- 绝对值太小不做分母
- 大数不要减小数
- 简化算法。
2. 插值
2.1. 概念
个点的插值函数存在且唯一。
线性插值
即两个点插值,参考拉格朗日情况。
二次/抛物线插值
三个点插值,设插值函数为,然后带入求解即可。
2.2. 拉格朗日插值
插值多项式为
满足,其中插值基函数为
插值余项为
2.3. 牛顿插值
是一种迭代插值方式,可以复用之前的计算内容,插值多项式为
差商
一阶差商(均差)
阶差商
阶差商和阶导数关系。
计算的时候写成差商表。记住分母就是分子里是分母就是。
回到牛顿插值,其系数则等于,最终插值多项式为
其插值余项为
2.4. 牛顿等距插值
差分
已知等距节点。
记向前差分/前差算子为
向后差分/后差算子为
中心差分为
高阶差分
规定零阶差分:。
阶差分为,其他同理。
和差商关系
计算时写差分表,倒三角矩阵。
此时可得牛顿等距插值多项式为
2.5. Hermite插值
当知道和一阶导数时使用。
对于阶插值式,有个已知数,此时令为次多项式,且满足
其中
为克罗内克(Kronecker)符号。 则有。
令,显然有。
且,有。
联立解得
令,同理可得
3. 曲线拟合
3.1. 函数逼近
最佳一致逼近
即MAE最小
最佳平方逼近
取。
对于线性空间
称为生成集合的一个基底。
解题时则对应不同得空间定义
然后目标是最小化。
则利用列方程组,即可解出得到。
矩阵形式求解则先求内积
然后有
3.2. 最小二乘法
相当于是散点函数拟合,只是一些算子计算方式变了,思路同上。对于和,我们同样也是找拟合,具体做法为
设为拟合函数,基函数为,有
(内积为)
解出后,即得到拟合函数,其对应的平方误差为
4. 数值积分
4.1. 插值求积公式
梯形公式:
把区间分成两份。
辛普森公式:
把区间分成六份。误差:。
对于任意插值多项式,有效数字
其中求积系数和,其求积余项。
代数精度:对于阶多项式准确且对于阶不准确则代数精度为。
已知公式求精度解题时则分别取,带入等式两侧。
找到不相等得阶数得到代数精度。
具有个节点的插值求积公式至少有次代数精度,反过来如果不符合这个则说明公式不是插值型的。
已知精度求等式时也一样,分别取,带入等式两侧获得方程组求解待定系数。
4.2. 收敛性&稳定性
- 不在复习范围。
4.3. 牛顿-柯斯特求积公式
- 不在复习范围。知道这个公式是上述各个公式的通项即可。
4.4. 复化求积公式
求积节点增加,直接使用牛-柯求积公式会放大误差。所以采用分区间分别求积的方式。
复化梯形
将区间分为份,步长,求积节点为。
有
推导即对每个小区间分别使用梯形再加起来即可,过程略。其求积余项/误差为
复化辛普森公式
其求积余项/误差为
记还是好记的,记住梯形是1阶的,所以余项是2阶,辛普森是3阶所以余项是4阶。
4.5. 龙贝格求积公式
- 不在复习范围。
5. 线性方程组的数值解
5.1. 消元法
- 首先需要把原方程组换成矩阵形式,这样也就是求解。
顺序高斯消元
就是线代中的非齐次方程解法,增广矩阵转为三角矩阵然后一一求解,求解前提是的任意主子式。
这里引入记符代表第次迭代后的元素,代表对原矩阵的第次消元/迭代步骤结果。
列主元高斯消元
直接消元运算过程可能会扩大误差,先找到列主要元素再消元,列主元为每列绝对值最大元素,使用这一行对其他行进行消元。
这里注意。
5.2. LU分解法
每一步消元可以看成是左乘一个初等下三角矩阵,
其中
也就是第次迭代时的初等矩阵第列为。我们有,则
令,此时原方程可以写成
实际解题时使用Doolittle或Courant对进行分解得到。
Doolittle法
对于

有
即的第一行就是第一行,第一列就是第一列分别除以第一个元素。随后同样迭代有
这里是的第行等于第行的元素减去第行和第列的内积。的第列是第行减去第行和第列的内积除以。
但是上述计算太抽象了(实际上从代数理解是对正交化的过程,但是手写计算太麻烦),一般我们使用类似增广矩阵变换的方式通过得到,例如
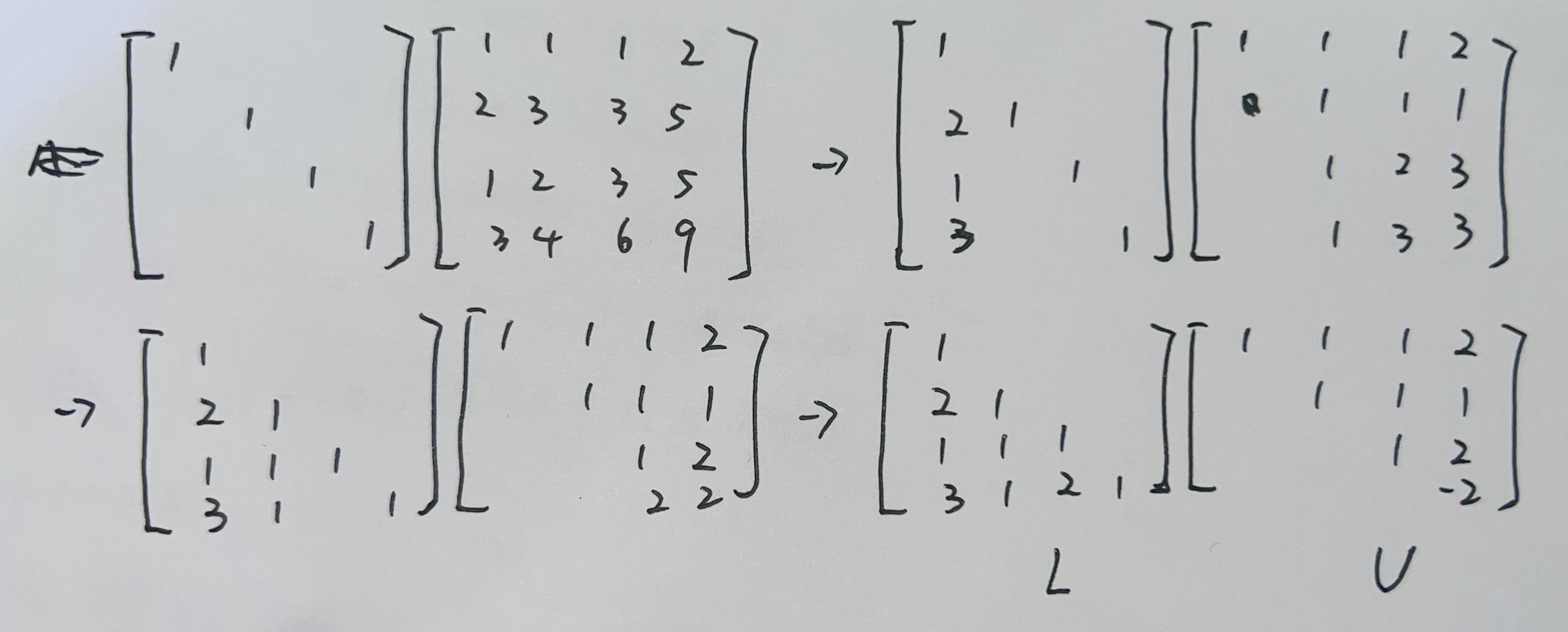
其中每次计算右侧矩阵消元的倍数更新到左边矩阵,同时更新右边矩阵为消元后结果,最终得到和。
Courant法
和Doolittle类似,只是变成了单位上三角,变成了一般下三角。要算的话可以还是先Doolittle分解,然后对每一列主元单位化,同时对每一行乘上相应数值即可。
例如上述就是最后一列分别除以,最后一行分别乘上即可。
Cholesky分解、追赶法
不在复习范围。
5.3. 矩阵范数
定义向量p-范数为,取无穷时范数为的最大元素绝对值。
对于方阵有F-范数(Frobenius)
方阵其他范数有
1-范数就是最大的列和(所以也叫列范数),就是最大行和(所以也叫行范数),真正的2-范数为的最大特征值(求解方法是)。
推广到任意矩阵列范数和行范数任然成立。
5.4. 误差分析
- 不在复习范围内。
6. 线性方程组的迭代解
6.1. 基本迭代方法
对于,设,构造迭代
Jacobi迭代
方程组转化为
解题时一般就是画迭代表,第一列为迭代次数,每一行为第次迭代的解。
Gauss-Seidel法
在迭代中使用最新解,例如计算出后,对于的计算中使用替代,后续同理。
6.2. 收敛判别
在Jacobi法中,将记为(这里的分别是的负值下上三角阵,和前面的LU分解法无关),为对角阵。
则,即。
对于Gauss-Seidel法,
定义
则有,迭代收敛的充要条件为
即,其中谱半径代表的最大特征值绝对值。
解题的时候就是先分解得到矩阵,然后根据计算特征值,有些时候算不出来则通过罗尔定理判断根的区间,从而得到的不等关系进行判别(一般不用)。
还有如果是严格对角占优,即对角元素绝对值均大于其他值,则收敛。
或任意范数(解题一般计算1和无穷),则收敛(但这个只是充分条件,不能判别发散)。
还有不可约对角占优、对称正定情况...应该用不上。
6.3. 松弛迭代法
- 不在复习范围内。
7. 非线性方程组求根
对于,解为,则可以写为
若则为重根。
7.1. 二分法
确定有根区间,罗尔定理判定。
假设
计算,若,则,反之。
终止条件为,得到迭代次数。
7.2. 迭代法
将改为。即可进行迭代求解
收敛的值为不动点。
收敛性
若在上不动点存在且唯一,若
则该迭代式将收敛到不动点。反之则发散。
收敛速度
若
则收敛速度为阶。
这里计算时利用拉氏中值定理有
。
按此我们可以继续推广至的阶导,原极限。则若
有为阶收敛。
7.3. 迭代加速
计算了和后,由艾特金加速法计算
将作为新的再次计算更新得到。
7.4. 牛顿法
对于近似解处一阶泰勒展开式有,则可得迭代公式
牛顿法至少为二阶收敛。
8. 常微分方程
- 对于常微分方程,我们将区间分为份,步长为,即。
8.1. 欧拉公式
将区间分为多个段求其斜率作为导数来迭代拟合。
令。迭代即可得到对。
8.2. 梯形公式
将原微分方程两边积分,用梯形公式计算其积分项,有
8.3. 改进欧拉公式
上述梯形公式是个隐方程,所以我们用改进欧拉,计算出第一次迭代后带入梯形公式做一次校正。
预测时, 校正为
8.4. 龙格-库塔公式
- 不在复习范围内。