Overcoming catastrophic forgetting in neural networks
Overcoming catastrophic forgetting in neural networks
arxiv: 1612.00796
序列化的学习方法对AI发展至关重要。而目前连接型的神经网络存在灾难性遗忘问题,本文提出一种方式可以克服这个问题,使得训练的网络能够长时间保存知识。该方法通过选择性地减缓任务的重要程度来记住旧任务。通过MNIST数据集的分类任务和Atari 2600游戏任务实验证明了该方法是可扩展和有效的。
EWC
核心思想
与人工神经网络形成鲜明对比的是,人类和其他动物似乎能够以持续的方式学习。最近的证据表明,哺乳动物的大脑可以通过保护新皮层回路中先前获得的知识来避免灾难性的遗忘。当小鼠获得一项新技能时,一定比例的兴奋性突触得到加强;这表现为神经元的单个树突棘体积的增加。至关重要的是,尽管随后学习了其他任务,但这些扩大的树突棘仍然存在,这是几个月后保持性能的原因。当这些刺被选择性地“擦除”时,相应的技能就会被遗忘。这提供了因果证据,表明支持保护这些增强突触的神经机制对于保持任务绩效至关重要。总之,这些实验发现与神经生物学模型一起表明,哺乳动物新皮层的持续学习依赖于任务特异性突触巩固的过程,其中关于如何执行先前获得的任务的知识被持久地编码在一定比例的突触中,这些突触的可塑性降低,因此在很长一段时间内都很稳定。该算法会根据某些权重对以前看到的任务的重要性来减慢学习速度。我们展示了如何在监督学习和强化学习问题中使用EWC,以按顺序训练多个任务,而不会忘记较旧的任务,这与以前的深度学习技术形成鲜明对比。\footnote
本文提出了一种弹性权重整合算法(EWC),核心思想是降低重要权重的学习率来减少遗忘。
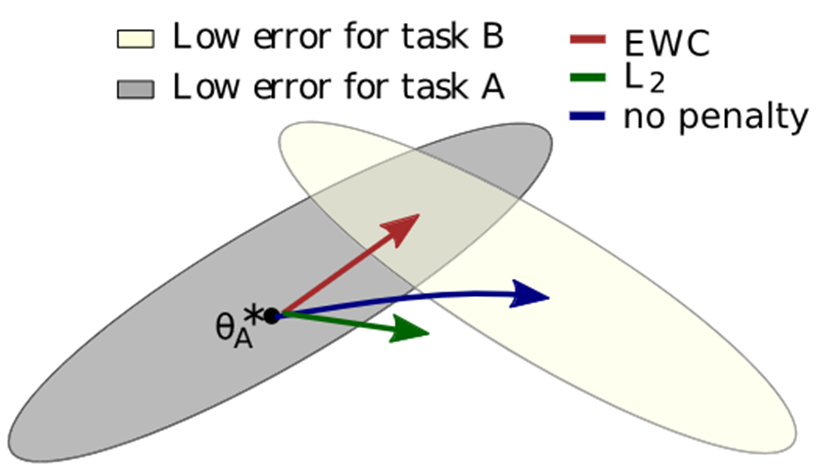
alt text 对于不同的两个任务我们假设其数据集分布如图1所示。其中灰色区域代表旧任务的低误差区域(即较优解域),黄色区域为新任务分布。如果直接使用旧任务的权重初始化网络,用新任务Fine-tune的话,优化方向如蓝色箭头所示,即网络只会认为黄色区域是优化目标而前进,会快速脱离灰色区域(灾难性遗忘)。 如果每个参数都用相同的系数约束的话,网络可能不能学习到B的内容。EWC则是对任务A中特别重要的限制较大,对不那么重要的参数限制较小。
约束选择
对于贝叶斯公式
其中称为后验概率,为先验概率,一般来说,先验概率是对事件的初始判断,例如抛硬币的概率可以认为是0.5,而后验概率即由于制材等问题,实际观测中概率可能不是0.5。其中这些影响先验的信息即,我们可以通过贝叶斯公式不断修正概率得到真实概率。
EWC的目的是找到对于一个数据集最重要的那些参数。假设这个参数为,我们的优化目的即找到最大的后验概率(即在中找到最优解)
然而我们不可能尝试每一个, 所以我们可以通过贝叶斯公式转为先验概率
假设由两个相互独立的数据集构成,上述公式可以转为
此时任务的对数似然可以看成就是任务的损失函数相反数(即取解时预测值和真实值的残差,近似为取负),记其为。为常数,最终网络优化目标为
拉普拉斯近似
上述目标函数取反得到最小化目标函数
此时,我们得到了损失函数中的约束项即的后验约束。但很显然我们依然无法求解该后验概率,EWC采用拉普拉斯近似的方式对该式进行替代。
令先验符合高斯分布(即认为数据集符合高斯分布),有
两边对数得
令,在处进行泰勒展开,有
由于为最优解,为驻点,则有
可解得,又由贝叶斯公式可得后验概率同样符合高斯分布,则有
由于为常数,故我们的优化目标可以化为
费雪矩阵
最终二阶导的Hesse矩阵是一个阵,EWC使用费雪信息对角阵进行替代。
费雪矩阵本身等于Hesse矩阵的负期望
如果只取对角线元素有
最终,网络的损失函数为