Yale/UNC-CH GWI竞赛
Yale/UNC-CH GWI竞赛
高分笔记
- 这里主要记录竞赛中其他团队公开的笔记。
HGNet-V2-Starter
链接见[1]。
根据作者介绍,这篇笔记思路源于另一篇笔记UNet with float16 dataset[2],其中UNet笔记内容简要如下
- 网络:Unet+ResidualDoubleConv [32-64-128-256-512-1024-512-256-128-64-32-1]
- 数据集:没有使用原始float32数据,而是使用float16数据加载训练网络。显然可以减少显存占用(64批次大小只需要7G显存训练)和加速训练时间。
本篇笔记主要工作是:
- 翻转增强
- 数据预处理
- EMA
- 编码器预训练
- Monai上采样(医疗图像分析工具库)
数据预处理
- 作者首先使用插值将地震数据变成大小,减少了大小。
翻转增强
我的理解是这是互易定理的作用,即让地震数据沿着时间轴+水平轴翻装,变成从接收器反向传播到震源。
这样可以在训练时获得更多输入样本
测试可以利用此增强模型结果(感觉非常类似这几天爆火的parallel scaling思路)
网络模型
UNet结构
编码器使用
timm(stride=1),解码器去掉了BN,跳跃链接中增加了中间卷积(intermediate convolution)训练细节
Adam(lr=1e-3)+L1 loss+EMA推理
训练三个模型,加权平均作为最终输出。
很有意思的工作,最终公开得分
60.9。
ConvNeXt - Full Resolution Baseline
链接见[3]。
和上篇HGNet是同一个作者,这篇主要是使用了一种新的网络。
作者这篇使用完整数据进行训练,主要工作是:
- 激活值swap
- 归一化swap
数据集使用float16数据集,同样做了翻转增强操作。
网络结构还是UNet结构,使用ConvNeXt Block替代ResNet Block。
编码器使用
stem进行降采样。使用InstanceNorm2d进行归一化。解码器去掉了中间卷积。其他细节同上一篇。
最终得分
36.4,个人认为主要还是使用全尺寸数据带来的性能增强。
2nd place solution with code: refinement with FWI
链接见[4]。
作者没有训练新的神经网络,而是在ConvNeXt的基础上使用传统FWI进行优化,作者使用正则化的FWI,即找到最小化
其中是速度模型,是成本函数,是的正演地震数据,是实际地震数据。
作者将数据集分类四类分别使用不同的成本函数进行迭代。
FlatVelA+B
对于平层,作者定义成本函数为
然后使用BFGS进行迭代。
StyleA
作者对于StyleA设置了具有平方指数核的高斯过程(噪声、偏移和斜率为超参数),再使用最大似然估计在训练集上调整超参数。
由于StyleA中实际没有噪声,得到的协方差矩阵非常病态(无噪声导致不满秩,最小奇异值为0,条件数为无穷大,在数值计算中表现为结果严重偏离),作者通过截断奇异值分解解决病态问题(具体为保留前1073个奇异值)。
整个过程为先通过BFGS优化,再通过高斯-牛顿进一步迭代。
StyleB
同样使用高斯过程,但不同的是StyleB噪声非常大,几乎完全接近没有正则化的状态,作者使用1500次BFGS迭代,基于梯度准则终止高斯过程。
其他模型
其他所有数据使用和Flat类似方法,但是使用2D总成本进行迭代,成本函数为惩罚点与其相邻点之间的绝对差异,即TV正则项。
然后通过3个BFGS进行优化。
| 数据集 | 先验 | 策略 | 分数 |
|---|---|---|---|
| FlatVelA+B | 1D TV | BFGS | 0.0 |
| StyleA | 高斯过程,SVD截断 | BFGS->GN | 3.4 |
| StyleB | 高斯过程 | 2x BFGS | 44.4 |
| 其他 | 2D TV | 3x BFGS | 4.9 |
最后,关于如何将数据分为上述四类,作者没有引入额外的分类模型,而是直接基于先验知识
- 如果地震记录对称,则为FlatVelA+B。
- 如果速度剖面的对数似然低于阈值
exp(13),则为StyleA。 - 如果速度剖面最大平坦区域小于阈值
95,则为StyleB。 - 否则则为其他数据。
作者QA
- 在帖子的留言中依然有一些有价值的内容。
如何调查私有与公开测试数据的分布?
由于Kaggle测试数据包括公开和私有两部分,而官方并没有公布各个子集在占比数据中的占比,如何知道你的模型在公开测试集中某个子集的得分是一个问题。
例如对于一个分类模型,你将完整测试数据识别出了一个子集StyleB,现在你想知道模型在公开测试数据中StyleB子集上的得分,但不知道公开测试集中有多少数据属于StyleB。
我们设为公开测试集中StyleB的比例,为模型在StyleB子集上的得分,为模型在非StyleB数据上的得分。
作者方案为:
- 正常提交,此时公开测试集总分。
- 对所有StyleB样本的预测值认为增加,此时得分为。
- 对所有StyleB样本的预测值认为增加,此时得分为。
此时我们便得到了三个方程,便能够解出最初的三个未知数。由此可以得到各个子集的数据占比以及模型表现。
有人继续留言是否这个方案依赖于一个完美的分类器(即如果最开始的分类有错误便会引入误差),作者认为由于数据足够多,且目前分类器效果足够好(99.55%+),这个错误可以忽略。
为什么使用BFGS/高斯过程而不是梯度下降?
作者认为大众现在习惯于训练神经网络,梯度下降已经成为处理非线性优化问题的默认选择。然而对于低维问题,它通常并不是最优选择。
因为梯度下降忽略了海森矩阵(因为高维计算二阶导数代价太大),导致在低维问题(特别是病态条件数问题)时收敛会变得非常慢。
不过这里作者并没有做实验比较,只是直觉判断。
1st Place Solution
- 链接见[5]。
预处理
作者将原始输入调整到的输入,获得分数为,然后将输入调整到,分数提升至
作者认为分数提升的原因是原本独立的通道被强制映射到空间网格上,引入了局部相关性,而卷积更擅长捕获空间局部信息。
架构
作者认为UNet并不是很好的选择,因为输入地震和输出速度模型在空间上没有对齐(350x350 -> 70x70),所以UNet中的跳跃链接反而会带来噪声。 所以作者使用ViT架构设计了回归模型。
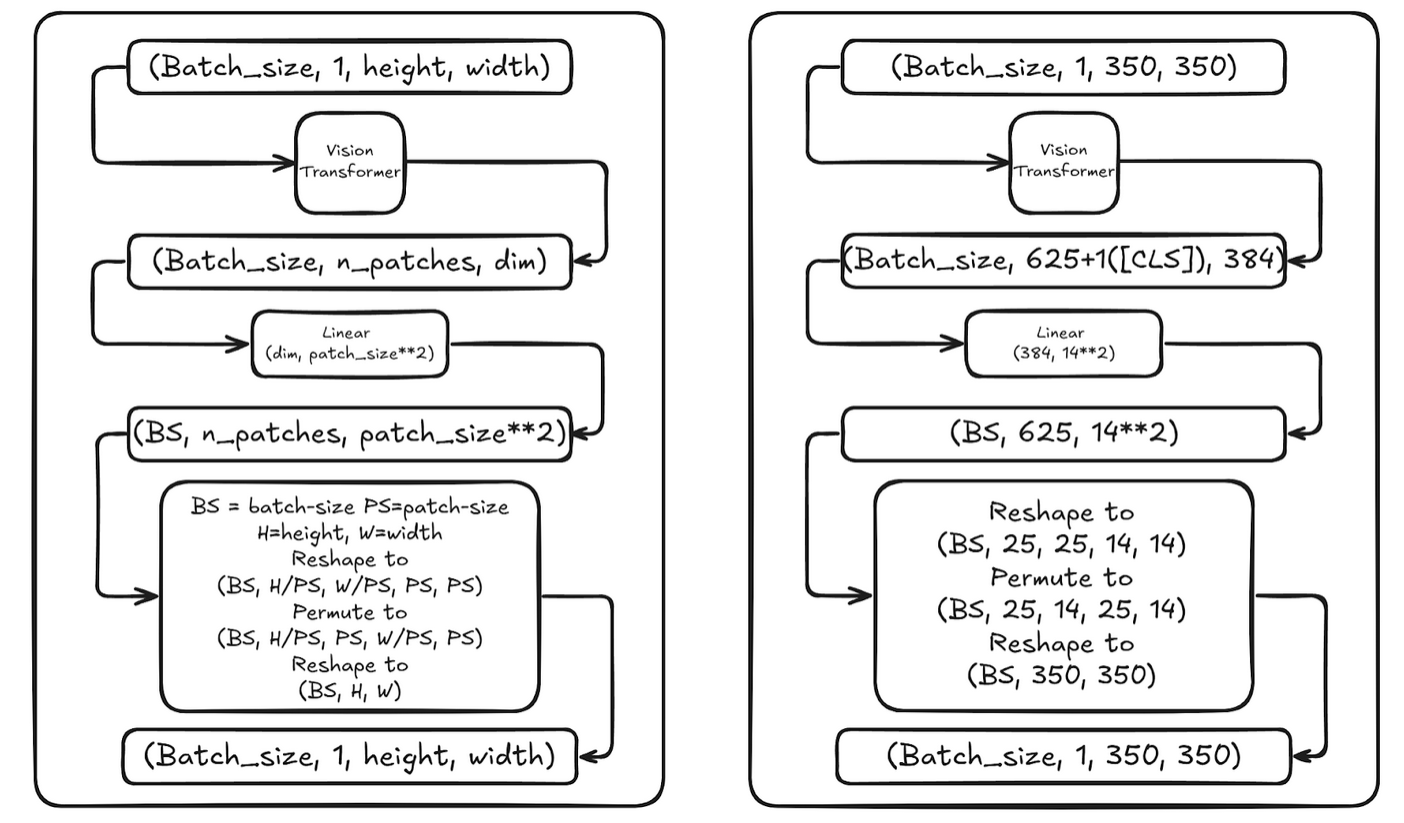
图1. ViT 由于输入是一个正方形,所以很容易处理。最开始作者直接使用ViT作为编码器+EVA02(一个视觉模型)进行回归便得到了接近30分。
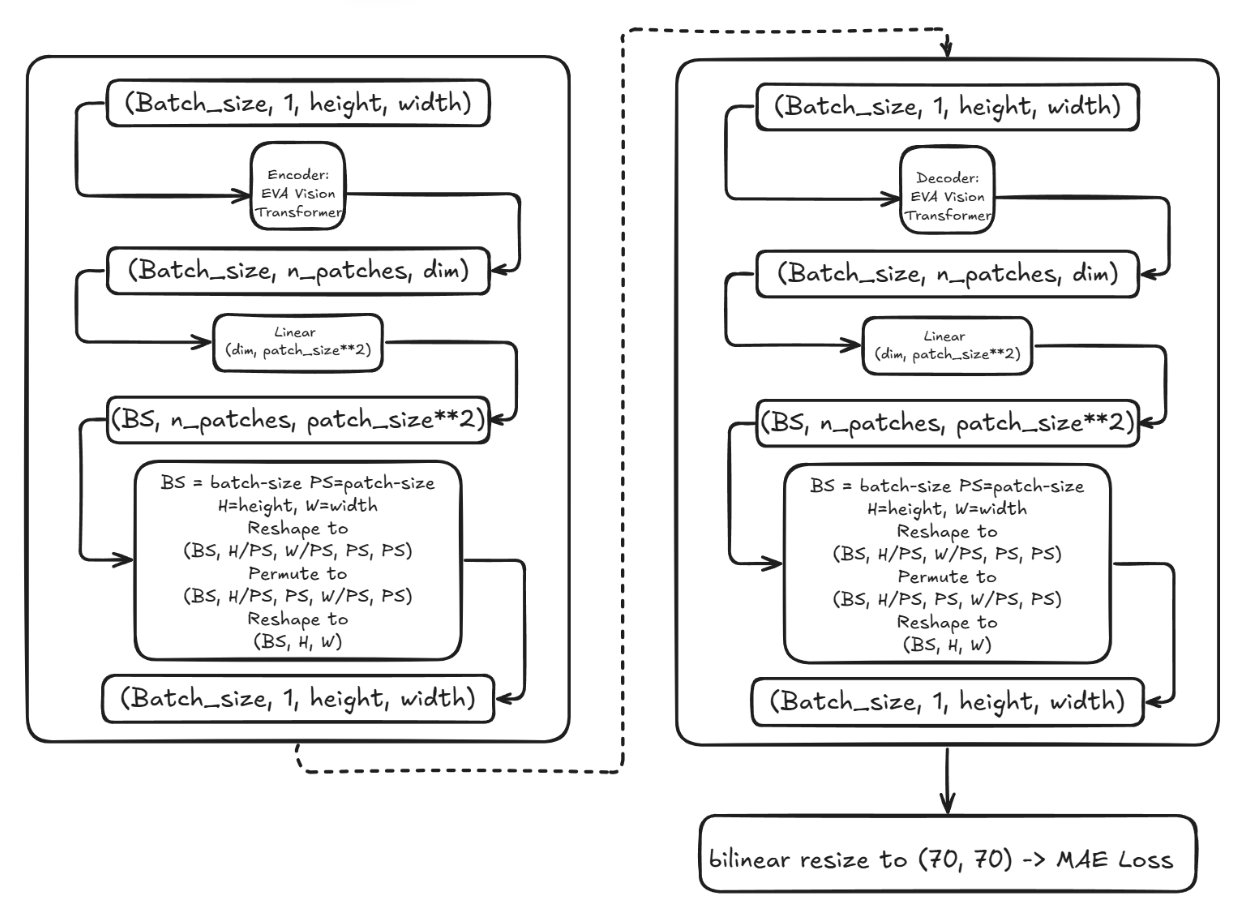
图2. 完整网络架构 完整网络架构为图2所示重复ViT作为编码器+解码器的结构。最终得分为,作者发现这个变体没有太大改变,反而过拟合了。
作者转而研究为什么EVA比ViT作为解码器要好(深度?通道?注意力头数量?MLP层?门控激活函数?),最终发现RoPE(旋转位置嵌入)是造成瓶颈的原因,随后作者选择了更好的预处理权重,并将
vit_small_patch14_reg4_dinov2.lvd142m作为主干网络。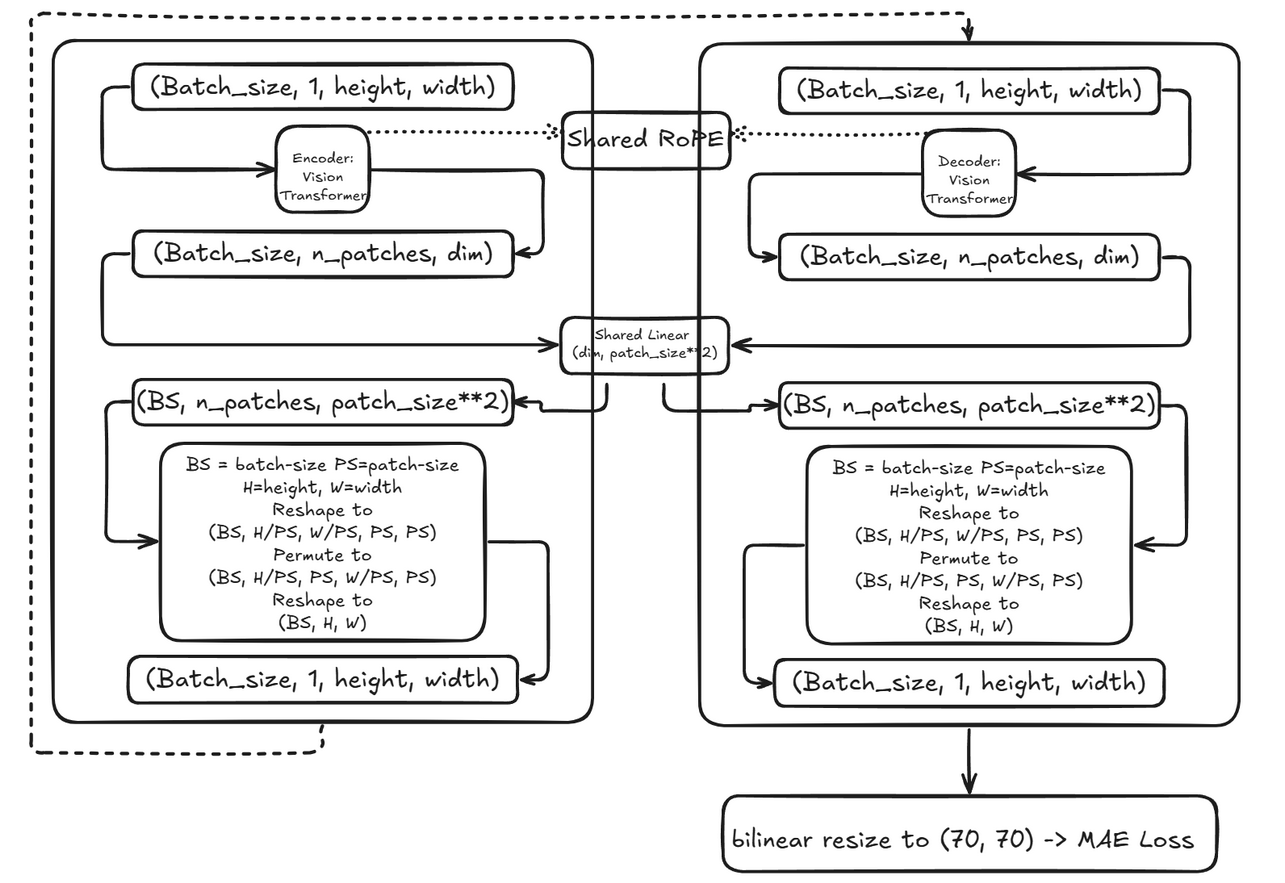
图3. 最终架构 图3为最终架构,得分26分。
训练
参数设置:
- LR:初始
1e-4,余弦退火到1e-5。 - 优化器:
AdamW。 - 损失:
MAE。 - HFlip、TTA、EMA。

图4. 训练过程 图4为训练过程,攻击300轮迭代,期间不断增加输入大小。以上便是作者最初的工作,后续作者进一步研究如何优化。
- LR:初始
数据增强
作者在现有速度模型上使用FiveCrop和5xRandomAffine进行增强(
RandomAffine(p=1.0, degrees=15, translate=(0.2, 0), shear=(-15, 15), padding_mode='reflection', resample='nearest'))来生成更多速度模型(10倍)。然后作者使用这些数据在上述训练的每个阶段之前进行预训练,结果如下。

图5. 预训练结果 然后作者使用称之为
伪预测的方式进一步优化,具体为在每一轮迭代后,使用当前模型对验证和比赛测试数据进行预测,然后对这些预测结果进行正演,并在下一次迭代中使用这些数据训练,效果提升非常可观。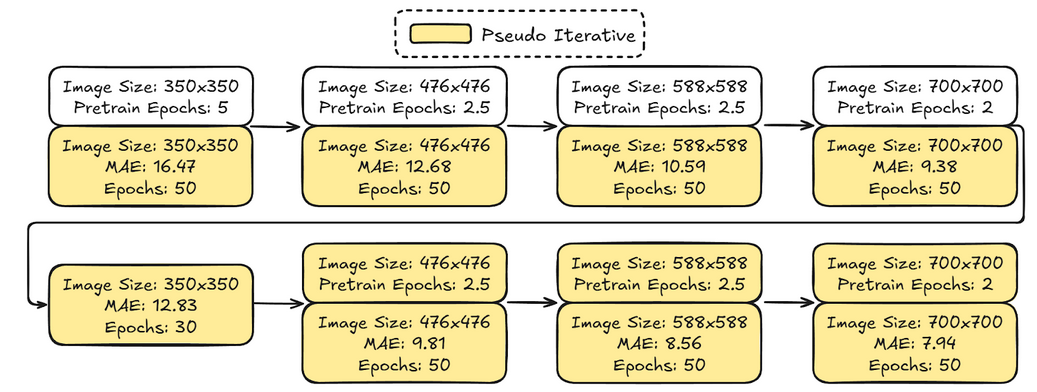
图6. 伪迭代训练结果 作者还发现模型在大部分数据集上几乎已经收敛,除了
CurveFaultB、CurveVelB、StyleA和StyleB,所以作者删除其他子集中一半的数据加快训练过程,让模型更多地关注这部分数据。
个人总结
数据处理
数据增强:
- 传统的标准图像处理在地震反演领域可能并不好用,使用基于震源-检波器反转的数据是有效的增强方式。
- 通道和空间信息,同样维度的数据由于其处理方式不同,也可能影响网络的性能。
数据剪枝:
- 面对大数据时,可以考虑下采样方案减少数据维度。
- MMAP内存映射到硬盘中+预读取方案应对显存不足的问题。
模型设计
- 医学领域+图像领域架构借鉴。
- TTA、EMA、动态学习率等调优方案。
- AMP混合精度训练减少显存占用。
Reference
https://www.kaggle.com/code/brendanartley/hgnet-v2-starter ↩︎
https://www.kaggle.com/code/egortrushin/gwi-unet-with-float16-dataset ↩︎
https://www.kaggle.com/code/brendanartley/convnext-full-resolution-baseline/notebook#Model ↩︎
https://www.kaggle.com/competitions/waveform-inversion/discussion/587950 ↩︎
https://www.kaggle.com/competitions/waveform-inversion/discussion/587388 ↩︎