Enhancing IoT Security with Asynchronous Federated Learning for Seismic Inversion
Enhancing IoT Security with Asynchronous Federated Learning for Seismic Inversion
地震数据/图像对于理解地下结构至关重要。然而,地震图像需要转换为能够识别地下层深度和厚度的速度图像才能进行准确的结构分析,这一转换通常通过地震全波形反演(FWI)实现。近年来,各种深度神经网络(DNN)被提出用于替代FWI,经过良好训练的DNN通常计算成本更低,但能生成与FWI相似的速度图像。然而,DNN模型的训练需要将现场地震接收器采集的地震数据传输到集中式数据中心,这会带来数据隐私和安全问题。地震现场测试通常在偏远地区进行,这些地方缺乏数据中心和互联网基础设施,因此无法实时训练DNN并实现地震反演。本文提出了一种用于地震反演的异步联邦学习(AsyncFedInv)框架,该框架利用多台边缘计算板等物联网设备,通过新颖的异步联邦学习方法协同实时训练紧凑的UNet模型。其中,1)引入了陈旧度函数以缓解模型陈旧问题,2)对于生成相似本地模型的客户端,将暂停其训练,从而降低通信成本和能耗。仿真结果表明,AsyncFedInv在收敛速度与基线算法FedAvg相当的同时,训练损失更低,测试性能更优。
介绍
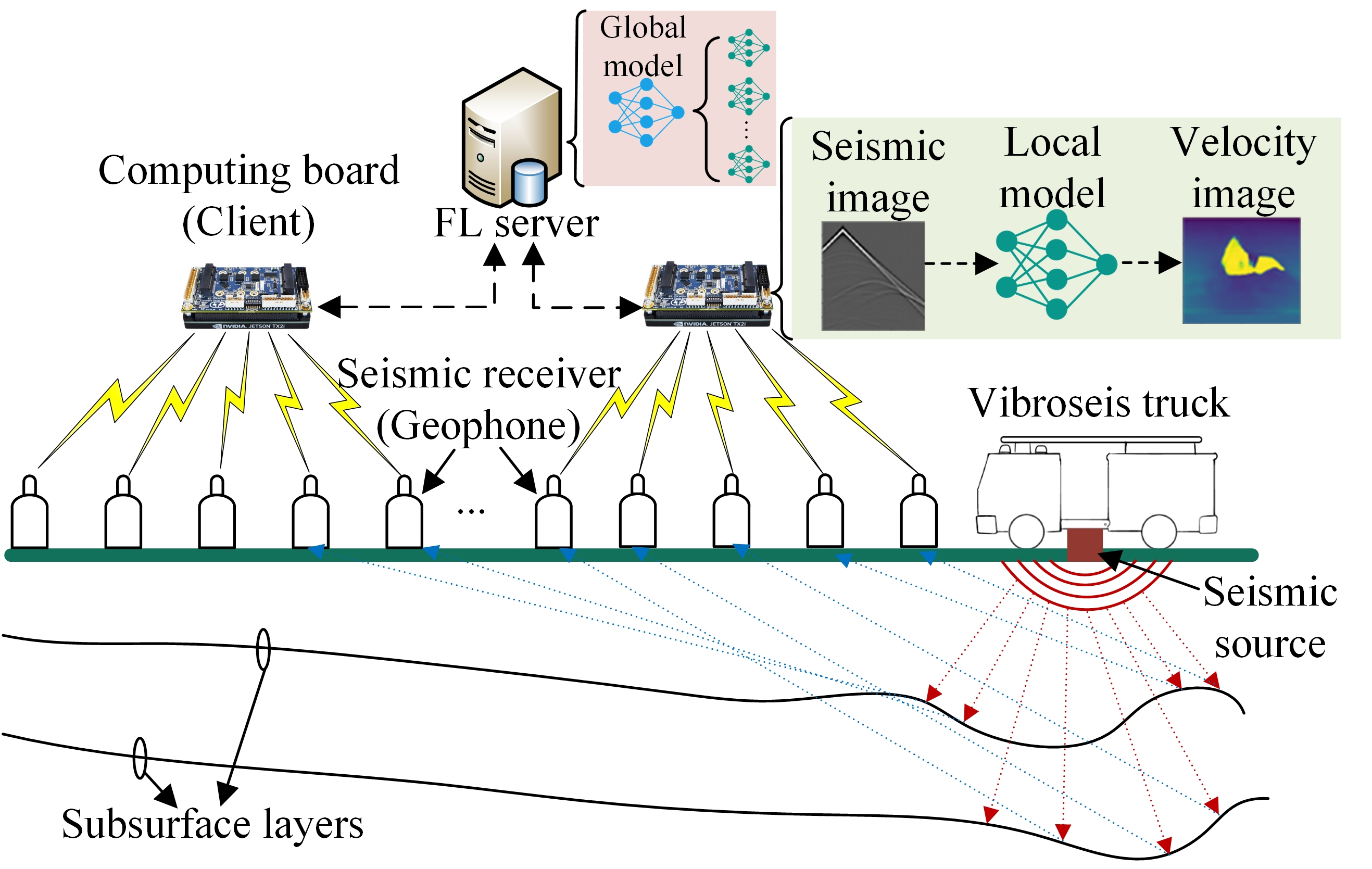
联邦学习地震反演 图1展示了地震收集与联邦学习训练过程,由可控震源车产生可控低频振动声波传至地下界层,这些波将被地下界层反射,再由部署在地面的一组地震接收机接收得到地震波。
然而,这些地震波还需经由FWI才可得到地下界层的深度和厚度。
FWI可以看作是最小化正演算子的MSE过程,即,其中为地震波记录,为速度模型,为通过得到的模拟地震记录。
目前,FWI的两个主要问题为:
- 计算成本高,每次FWI迭代中需要大量地震波场模拟和重建来最小化MSE;
- 对数据中的噪声和误差高度敏感,地震记录或初始模型的微小误差会在FWI生成的速度图像结果中产生重大偏差。
为了解决上述问题,深度神经网络(DNN)被应用与地震领域,其已被证明拥有较低的计算成本与较高的抗噪性。
包括:
- 使用FCN implement seismic inversion;
- 使用GAN transforms raw seismic waveform into velocity images;
- 使用DNN introduced a velocity prediction technique;
- SeisInvNet perform end-to-end velocity inversion mapping。
但上述所有方法都基于集中式方式进行训练,同地震接收器采集的数据必须传输到数据中心,这带来了数据隐私和安全问题。
并且地震测试通常在农村地区进行,缺乏数据中心和互联网基础设施。大量地震数据需要人工运输到数据中心,无法实现实时训练和测试。
本文引入联邦学习(FL)和边缘计算来解决这些问题,如图1所示,该设备以计算板(computing board)的形式上传其地震数据,每个IoT设备作为FL中的客户端存储和处理其接收的地震数据。 在此,FL允许不同客户端协作训练ML模型,而无需共享其地震数据,从而确保IoT数据隐私和安全。
整个训练过程分类一系列全局轮次,每个轮次分为四步:
- FL服务器(可以是测试场中的一个IoT设备)选择合适客户端,并向这些客户端广播当前全局模型。
- 每个选中的客户端使用本地地震数据独立训练接收到的全局模型,以获得本地模型。
- 选中的客户端随后通过无线网将其本地模型上传到FL服务器。
- 一旦接收到所有选中客户端的本地模型,FL服务器便进行聚合,使用例如FedAvg等方法更新全局模型。
全局轮次继续进行,直到全局模型收敛或全局轮次数量超出预定义的阈值为止。
上述过程被称为同步FL,其中FL服务器必须等待直到所有选中的客户端都上传了它们的本地模型,如果其中一个选中的客户端需要更长的时间来计算和上传其本地模型,这可能导致拖尾问题,从而增加全局轮次的延迟。
尽管已经提出了许多解决方案来缓解拖尾问题,但它们都带来了其他问题。例如,最流行的解决方案之一是设置截止时间,FL服务器只选择能够在截止时间前上传其本地模型的客户端,或者简单地忽略在截止时间后上传的本地模型。这种解决方案可能会因为有偏的客户端选择而降低全局模型精度,即FL服务器不选择慢速客户端,因此导出的全局模型可能无法适应来自这些慢速客户端的训练数据。
本文采用异步FL,当FL服务器从任何客户端接收到本地模型时便更新全局模型,再将更新后的全局模型发给该客户端。 异步FL没有拖尾问题,并允许所有客户端参与训练过程,但也包含两个突出缺点:
模型陈旧性(Model Staleness)
慢速客户端基于过时的全局模型训练其本地模型;因此,当FL服务器聚合来自这些慢速客户端的本地模型时,全局模型可能会降低其精度。
高通信成本
快速客户端需要与FL服务器更频繁地通信,从而导致高能耗。
本文提出了一种异步联邦学习地震反演(AsyncFedInv)框架,将异步FL和边缘计算集成到地震数据分析中,以实现实时地震反演,主要贡献总结为:
提出AsyncFedInv框架
边缘设备能够应用异步FL训练DNN(UNet),实现实时地震反演。是第一个探索将FL和边缘计算集成到地震反演的研究。
AsyncFedInv技术创新:
- 陈旧性函数(staleness functions):模型聚合过程中动态调整本地模型权重,从而缓解模型陈旧性问题。
- 动态客户端参与:本地模型与当前全局模型没有显著差异的客户端训练赞同,从而减少通信成本和能耗,同时保持模型精度。
大量的仿真实验
通过大量仿真实验证明AsyncFedInv的收敛性和模型精度。通过仿真评估了应用不同陈旧性函数时AsyncFedInv的性能。
数据驱动FWI(DD-FWI)设计
DD-FWI的目的是推导出一个由参数参数化的伪逆算子,其中
其中是不同地震接收器观测到的地震数据,是真实速度模型,是测量噪声。
在2D场景中,和的维度分别为和。
在DD-FWI中,通常实现为一个DNN,它学习从地震数据到速度模型的映射,中的参数基于给定地震数据集和对应速度模型图像上进行训练,其中速度图像可以基于物理FWI模型获得,该模型具有高计算成本但提供准确的速度图像。UNet的损失函数为:
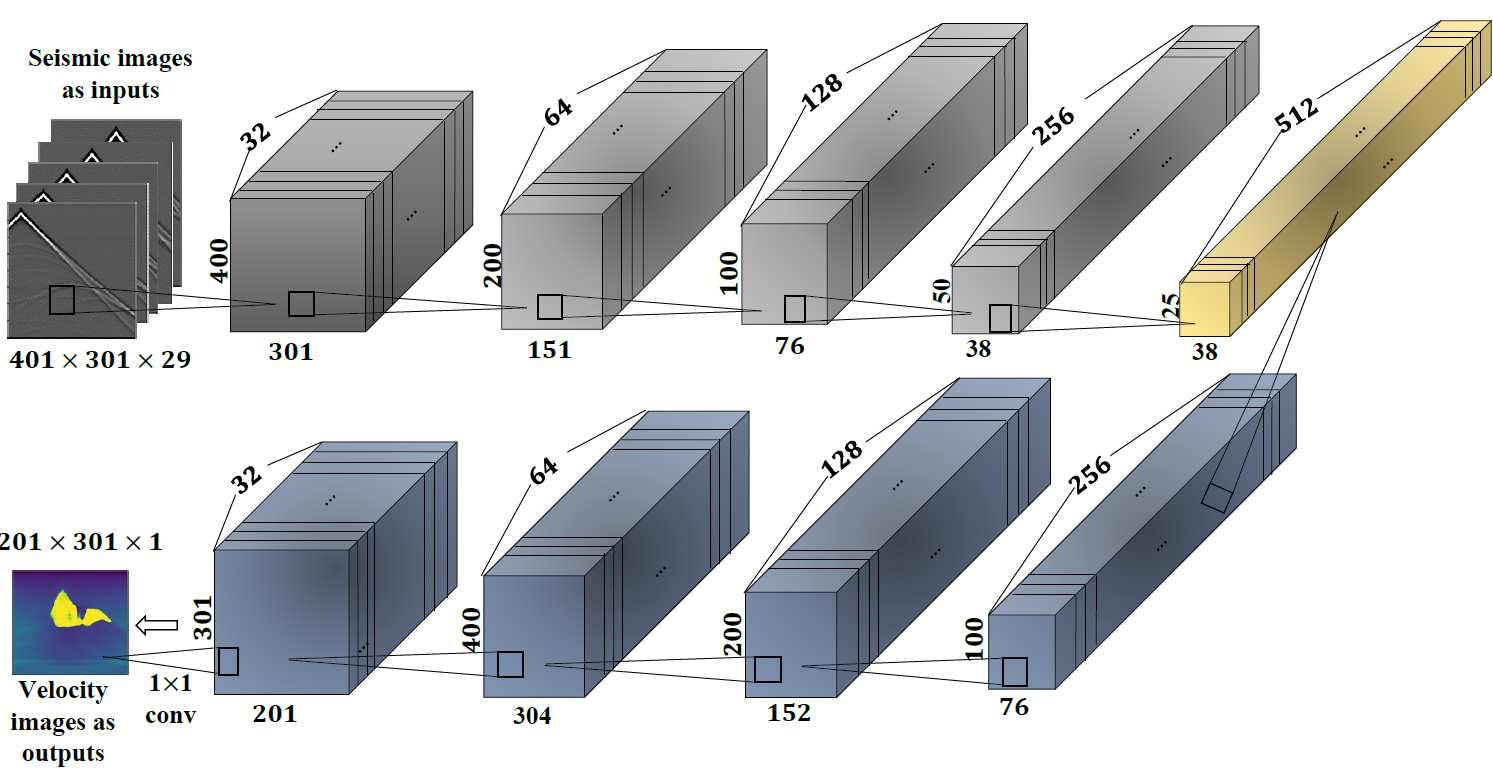
网络结构
系统模型
FL中的客户端用于协作训练UNet模型最小化全局损失函数,即
其中是全局模型参数,是客户端集,是客户端中地震数据和速度图像对的数量。是全部地震数据和速度图像对数量,为客户端的本地损失函数,即
然而问题(3)不是平凡问题,FL将问题分解,使每个客户端都能基于本地数据集推导出本地模型,以最小化损失函数,即
然后在FL服务器上聚合本地模型得到全局模型。
延迟模型
客户端的延迟包括:
- 客户端从服务器下载全局模型的延迟;
- 客户端计算本地模型的延迟;
- 客户端将本地模型上传到FL服务器的延迟;
- FL服务器更新全局模型的延迟。
通常,第四步中与全局模型更新的相关延迟可以忽略,因此客户端在每次迭代中的延迟定义为
计算延迟:假设客户端使用个地震图像训练本地模型,批次大小为,因此批次数为,另外,假设训练本地模型的本次迭代次数为
因此,在客户端的全局轮次中,前向传播和反向传播的次数分别为和。如果在客户端中对提出的UNet模型进行一次前向传播和反向传播所需的CPU周期数复杂度分别为和,那么客户端训练本地模型的计算延迟为:
其中是客户端的CPU频率。
下载/上传延迟:假设FL服务器使用时分双工系统(time division duplex system)将全局模型下发给客户端,同时客户端将本地模型上传给FL服务器,用表示FL服务器到客户端之间的信道增益(信号功率放大衰减变化量),并且信道具有互易性(上行和下行对等)。因此,客户端的下载和上传速率为
其中是总带宽,和分别是FL服务器和客户端的传输功率密度,是评价噪声功率密度。假设全局模型大小为,有
AsyncFedInv
全局模型接收本地模型时更新残差,即
其中是分配给客户端的权重。
陈旧性问题是异步FL的主要缺点之一,所以这些本地模型基于公式10更新全局模型时,它们可能不会改善全局模型的性能,甚至可能导致全局模型发散。
解决陈旧性的一种常见方法是调整,高时延的慢速客户端将会分配更小的权重,有
其中时超参数,是客户端的陈旧性函数,用户评估本地模型的新鲜度。 本文设计了三种典型的陈旧性函数:
- 常量:,平等对待所有客户端;
- 指数:;
- 铰链:
其中为超参数,。 这里是当前正在训练本地模型的客户端集合。
异步FL的另一个缺点是快速客户端的通信和计算成本高,也就是说,快速客户端必须频繁上传并持续训练其本地模型,从而导致高能耗。且能耗对于部署在农村地区并由便携式电池供电的客户端来说可能是关键问题。
本文采用了一种简单有效的方式,如果客户端上传的本地模型与更新的全局模型相似,则不发送更新的全局模型来暂停客户端的本地模型训练。即
其中是预定义阈值。
一旦FL服务器更新了全局模型,它将评估中的所有客户端,看公式12是否仍然满足,其中是暂停训练的客户端集合,且。
如果中的某个客户端不满足公式12,则FL服务器将发送当前全局模型来恢复其训练。
\begin{algorithm} \caption{The AsyncFedInv framework} \begin{algorithmic} \STATE Initialize $\theta^{\text{global}}$ and hyperparameters. \STATE Broadcast $\theta^{\text{global}}$ to all the clients. \STATE \textbf{At the FL server:} \While{receive a local model $\mathbf{\theta}_k^{\text{local}}$ from client $k$} \State Calculate $\alpha_k$ based on Eq. (11); \State Update $\mathbf{\theta}^{\text{global}}$ based on Eq. (10); \If{$\|\mathbf{\theta}^{\text{global}} - \mathbf{\theta}_k^{\text{local}}\| > \varepsilon$} \State Download $\mathbf{\theta}^{\text{global}}$ to client $k$; \Else \State $\mathcal{K}' := \mathcal{K}' \setminus \{k\}$ and $\mathcal{K}'' := \mathcal{K}'' \cup \{k\}$; \State Store client $k$'s local model $\mathbf{\theta}_k^{\text{local}}$; \EndIf \For{each $k' \in \mathcal{K}''$} \If{$\|\mathbf{\theta}^{\text{global}} - \mathbf{\theta}_{k'}^{\text{local}}\| > \varepsilon$} \State $\mathcal{K}' := \mathcal{K}' \cup \{k'\}$ and $\mathcal{K}'' := \mathcal{K}'' \setminus \{k'\}$; \State Download $\mathbf{\theta}^{\text{global}}$ to client $k'$; \EndIf \EndFor \EndWhile\State \textbf{At client :} \While{receive a global model } \State ; \State Train based on batch gradient descent; \State Upload to the FL server; \EndWhile \end{algorithmic} \end
仿真
仿真参数
使用三个客户端,优化器使用Adam,学习率,模型使用UNet。
数据集使用2D SEGSalt,共有120对地震/速度图像。
参数 值 本地模型大小 100 kbit 本地迭代次数 50 全局迭代次数 100 批次大小 5 陈旧函数超参数 10/4 公式10中的超参数 0.5 所有的120对地震/速度图像基于SSIM进行分组,即如果一个速度图像与某个类别中任何速度图像的SSIM不大于定义的阈值,则这对数据将被分组到该类别,由此将120对数据以不同设置分布到3个客户端,即独立同分布(IID)和非独立同分布(non-IID)。
在IID中,客户端每个类别具有相同/相似数量的图像,在non-IID中,假设客户端在类别中拥有对数据的概率遵循狄利克雷分布,即,其中是类别总数,是伽马函数,是集中参数,决定客户端内不同标签的标签不平衡程度。较大的导致客户端内不同标签之间的数据分布更加平衡(更接近IID)。
仿真结果
- 本文使用FedAvg作为基准算法(一种著名的同步FL),在每个全局迭代中邀请所有客户端参与模型训练。
训练损失和收敛性分析
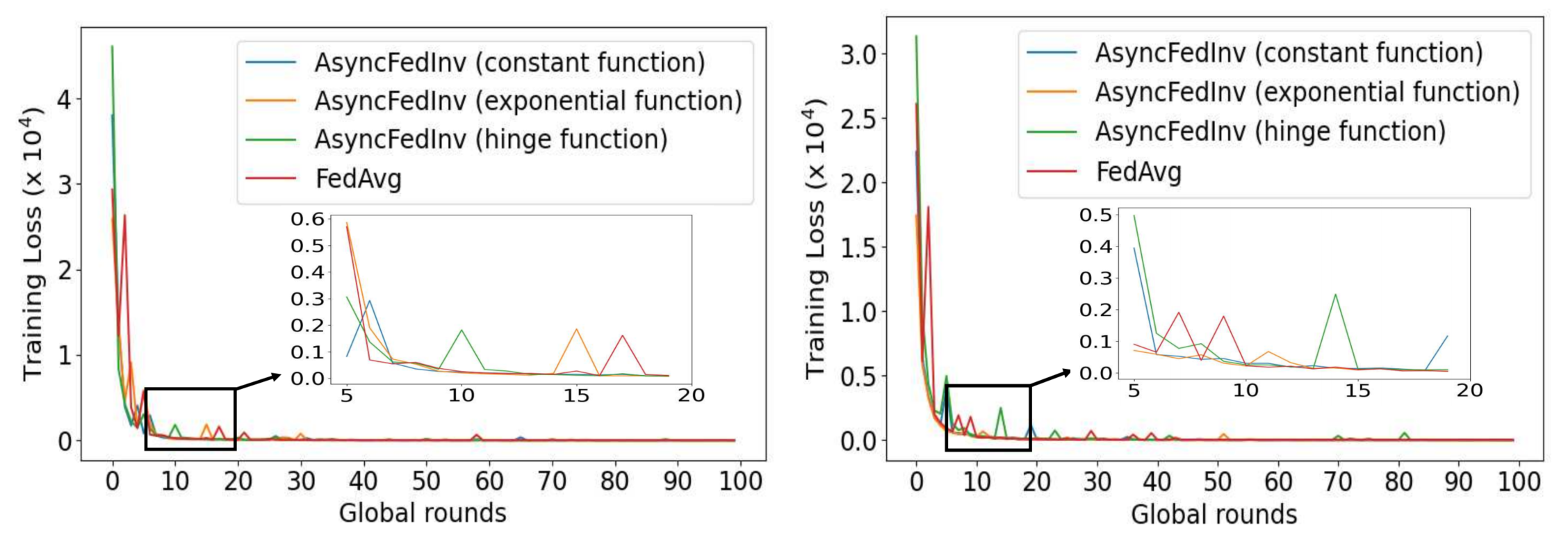
AsyncFedInv和FedAvg loss曲线,左为IID,右为non-IID() 由于异步FL没有全局轮次定义,本文将全局轮次的持续时间定义为最慢客户端计算和上传其本地模型所需时间。
从上图可以看到,在IID和non-IID情况下,所有方法收敛速度相似,但使用指数陈旧性函数的AsyncFedInv在曲线收敛时获得最低的训练loss。 在IID情况下,FedAvg、具有指数函数的AsyncFedInv、具有铰链函数的AsyncFedInv和具有常数函数的AsyncFedInv的损失分别为3.1449、2.2356、2.6344和3.2033。 在non-IID情况下,它们的损失分别为4.4193、1.7669、3.1383、6.4552。 因此,我们将在后续使用指数陈旧性函数作为AsyncFedInv的默认设置。
测试结果分析
上图显示了两种设置下的四个样本测试结果,可以发现在IID下AsyncFedInv得到的速度图像比FedAvg更接近真实值。在non-IID中,FedAvg的测试结果比AsyncFedInv要差得多。
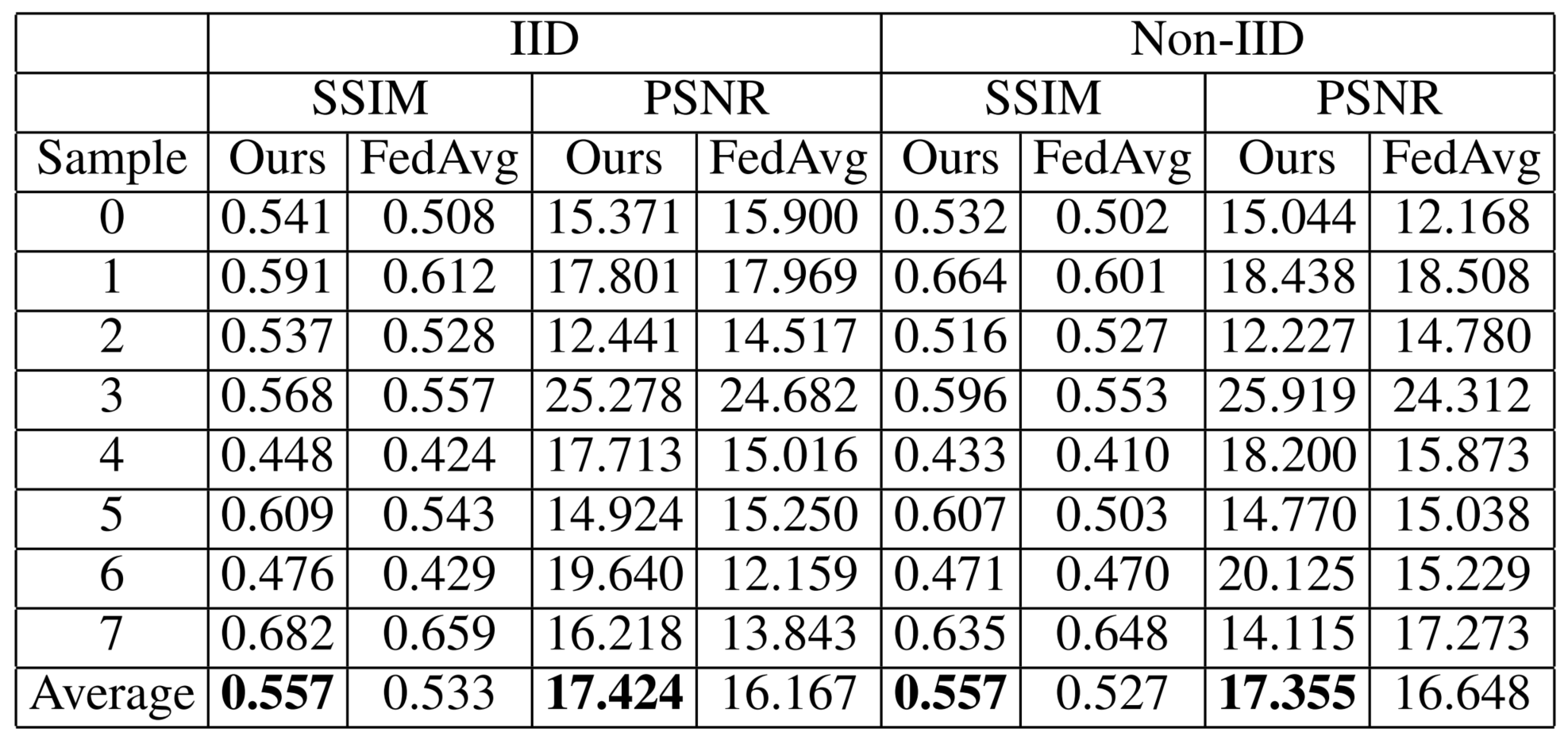
量化指标结果 作者还是用SSIM和PSNR进行量化测试,可以看出AsyncFedInv在IID和non-IID情况下都比FedAvg指标要高。
总结
本文使用多个边缘设备基于异步FL协作训了一个UNet模型,实现实时性能,主要贡献为:
- 使用陈旧性函数缓解陈旧性问题;
- 设计动态客户端参与减少客户端通信成本和能耗。