大模型轻量级微调方法:LoRA
大模型轻量级微调方法:LoRA
LoRA方法来自论文LoRA: Low-Rank Adaptation of Large Language Models。
如今各类通用LLM越来越多且越来越大,如果想将一个通用LLM适用于特定领域变得非常困难(因为你需要使用特定数据集重新微调整个网络),而LoRA提出了一种全新的低秩适配方式,通过冻结预训练网络参数,并在每一层Transformer中注入可训练的秩分解矩阵,大大降低了微调所需的训练参数量。
背景
LoRA并非第一个提出冻结+适配器这种微调方式的论文,方法的核心思想就是对于一个庞大的预训练网络微调任务,通过插入少量可训练模块(适配器)来代替原始参数进行训练,达到大幅度降低计算和存储的目的。
Houlsby Adapter 方法提出在Transformer的MHA和FFN之后添加一个Bottleneck网络(Down -> Activation -> Up)进行迁移学习。
后续一些工作开始探索组合多个模块化的适配器能否提高新任务性能,AdapterFusion/AdapterSoup 等方法提出组合多个任务适配器的知识来处理新任务以提高性能,其中Fusion引入一个融合层学习如何动态地组合多个适配器输出,Soup直接平均多个适配器参数。
再者,Compacter/IA3这类工作探索如何将适配器的参数缩减到极致。Compacter将适配器权重矩阵分解为共享的“低速”权重和任务特定的“高速”权重。IA3不引入新模块,而是直接将Transformer中的激活值替换为针对指定任务的可学习的缩放向量。
那么LoRA有何不同呢,首先上述其他工作的适配器大部分是串行插入的,即会破环原网络结构,而LoRA则是在原始模块旁边增加一个适配器并行处理输入再将输出求和。
LoRA的适配器核心和Houlsby类似,也是一个降维再升维的过程,其设计思想得益于Intrinsic Dimensionality Explains the Effectiveness of Language Model Fine-Tuning关于内在维度(intrinsic dimension)的发现,它指出大模型是过参数化的,在适配一个具体下游任务时,存在一个极低的内在维度。只需要对这个在极低维度的参数进行优化就能够达到全量参数微调的性能。
基于此,LoRA假设模型在任务适配过程中权重的该变量是低秩的,由此提出低秩自适应方法。
方法
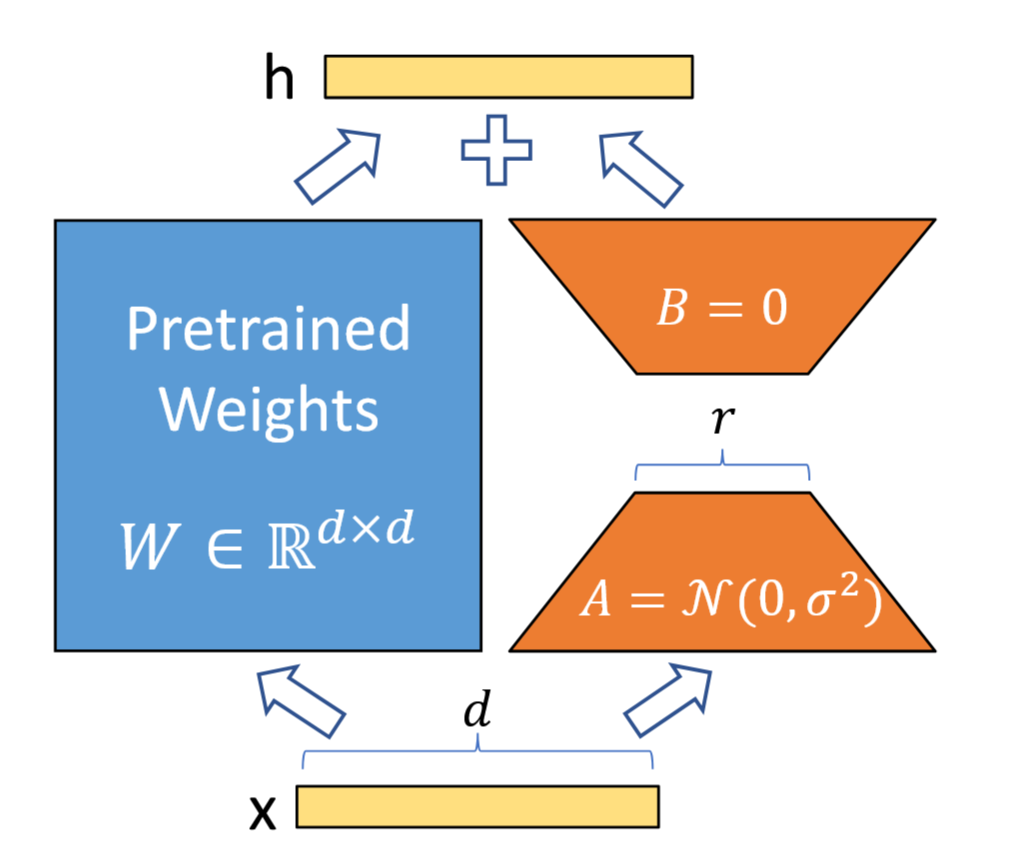
具体为在预训练权重(PLM)旁增加一个适配器。
用随机高斯分布初始化,用矩阵初始化,此举是保证训练开始时适配器矩阵依然是矩阵。 训练时固定PLM参数,只训练,此时前向传播为。 训练完成将合并回原始权重,后续网络推理无额外延迟。
这里的低秩体现在内在维度是远远小于原参数空间维度的,即,而。
容易发现,全量微调是LoRA的一种特例(),而由于内在维度的存在,我们便很容易理解为什么LoRA使用极小的训练成本以及零额外推理成本便可以达到类似全量微调的效果。
实验
精度
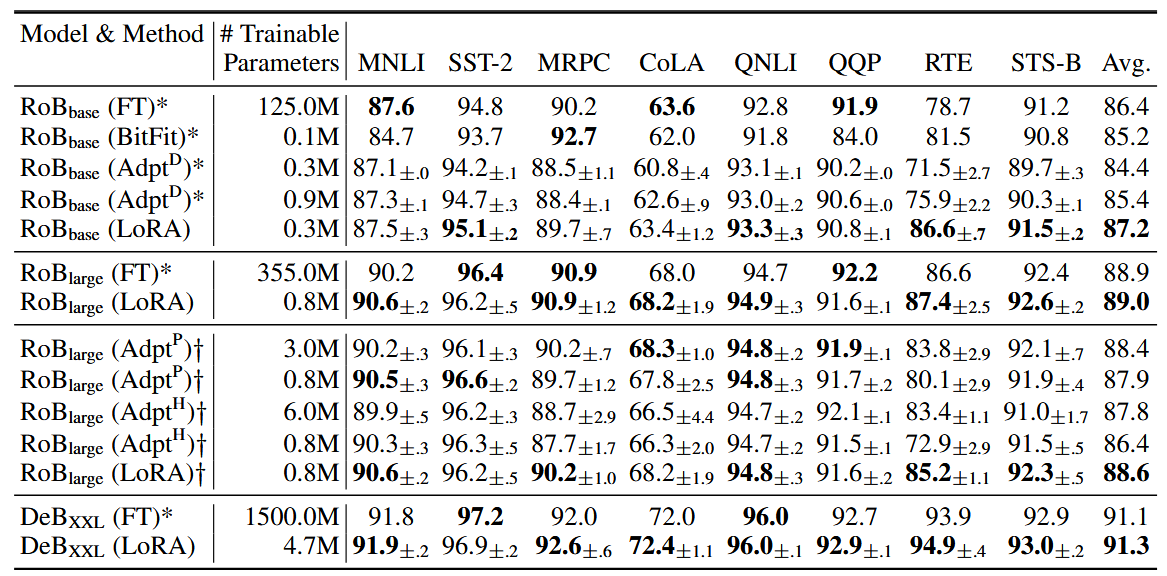
其中
- MNLI:该任务是一个自然语言推理任务,要求模型根据给定的前提和假设来判断它们之间的关系(蕴含、中立或矛盾)。数据集中包含来自不同文体(新闻、文学等)的句子对。
- SST-2:该任务是一个情感分析任务,要求模型判断给定句子的情感是正面还是负面。
- MRPC:该任务是一个语义相似度任务,要求模型判断给定句子对是否具有语义相似性。
- CoLA:该任务是一个语言可接受性任务,要求模型判断给定句子是否符合语法规则和语言习惯。
- QNLI:该任务是一个自然语言推理任务,要求模型根据给定的问题和前提,判断问题是否可以从前提中推导出来。
- QQP:该任务是一个语义相似度任务,要求模型判断给定问题对是否具有语义相似性。
- RTE:该任务是一个自然语言推理任务,要求模型根据给定的前提和假设来判断它们之间的关系(蕴含或不蕴含)。
- STS-B:该任务是一个语义相似度任务,要求模型判断给定句子对是否具有语义相似性,但是与MRPC不同的是,STS-B中的句子对具有连续的语义相似性等级。
从结果可以看出LoRA可训练参数最少,整体效果最好。
后续还有其他生成式任务以及更大的模型微调对比,同样是LoRA更好。
鲁棒
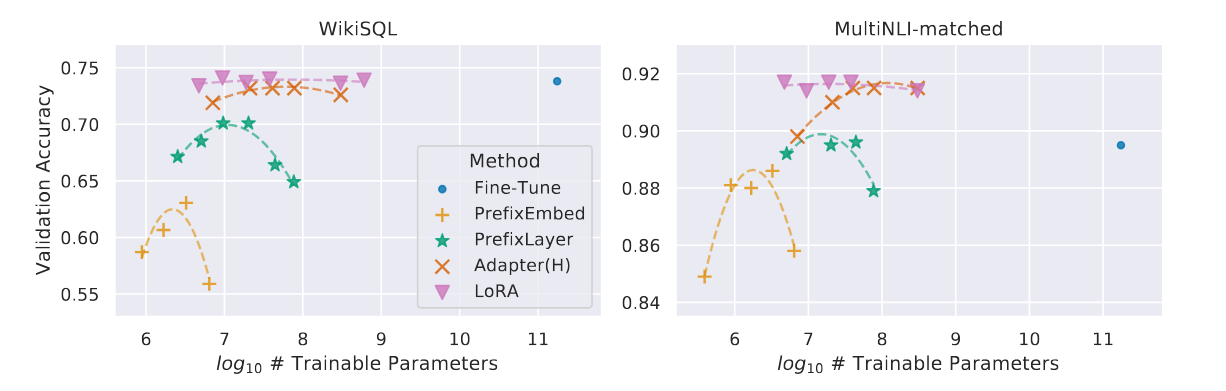
- 当增加微调方法适配器的参数量时,其他微调方法都出现性能下降的现象,只有LoRA的性能保持稳定。
结论
- LoRA性能与全量微调持平甚至超过
- LoRA相比其他微调方法,增加参数量不会导致性能下降。
其他
微调位置
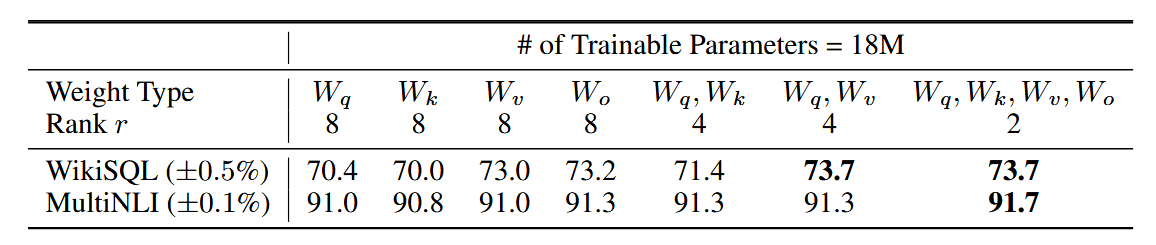
论文讨论了针对Transformer不同位置进行微调的结果,可以发现同时微调和可以获得最佳效果。
作者认为使用较小的秩也能在中捕获足够多的信息,因此调整多个权重矩阵比调整秩更大的单一类型权重更可取。
秩的选择
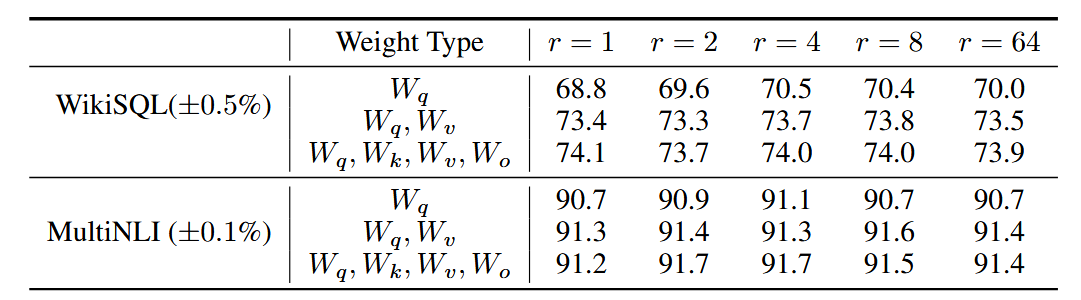
- 论文探索了不同值对性能的影响,可以发现一般性的任务即可,反而增加值并不能提升微调效果,作者认为可能是由于参数量增加而需要更多的语料。
参数初始化
为什么矩阵不能同时为?
因为如果都为则梯度也始终为0,无法更新参数。对于,此时有
若,则梯度都为0,BP中得不到任何更新。
为什么不是,随机?
可行,但原方案更优雅。
中可以看出是基向量,可以看成系数,则原方案是向量随机,系数为0,然后先确定在每个随机方向的强度,再优化方向本身,优化过程更加平滑。 而替代方案则是向量为0,系数随机,则此时的更新方向受到一个随机矩阵调制,可能会引导走不太优化的方向,可能会导致训练初期损失震荡更大。