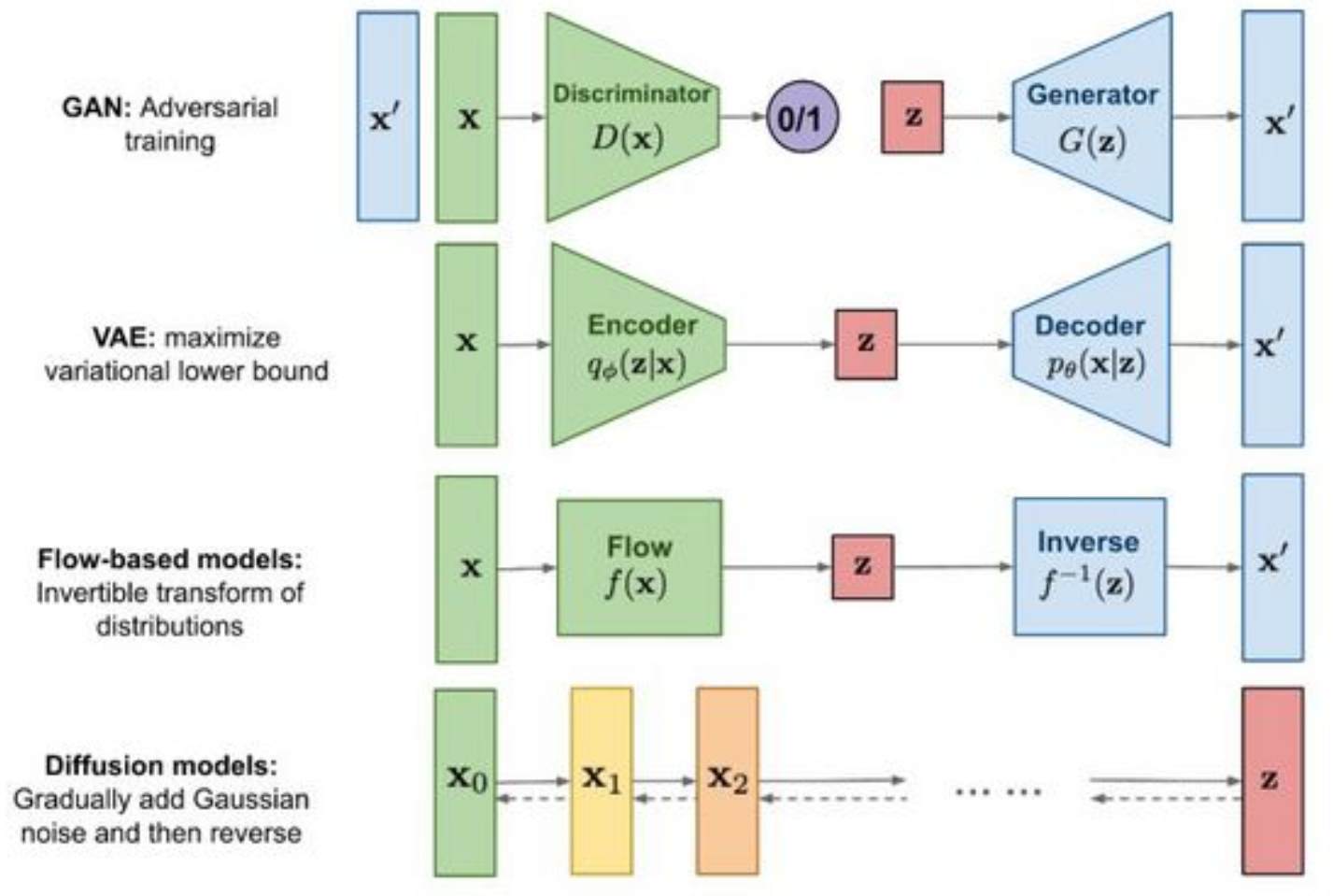
在这个过程中,原始图像x0会被添加T次噪声,使得xT符合标准正态分布。
但是这里的加噪声不是直接在上一张图片上“增加”(即修改数值)噪声值,而是定义一个均值和上一步图像有关的正态分布,再从该分布中采样得到下一张图像。即
xt∼N(μt(xt−1),σt2I)(1)
大部分的扩散模型将这个正态分布设置为
xt∼N(1−βtxt−1,βtI)(2)
其中βt<1,且{β}i=1T一般为一个递增序列,目的是为了随着t的增加,xt越来越接近纯噪声N(0,I)。 同时我们可以推导得到通项公式使得能够从x0直接计算xt。
设ϵt−1为标准正态分布,有xt=1−βtxt−1+βtϵt−1,则
xt=1−βtxt−1+βtϵt−1=1−βt(1−βt−1xt−2+βt−1ϵt−2)+βtϵt−1=(1−βt)(1−βt−1)xt−2+(1−βt)βt−1ϵt−2+βtϵt−1=(1−βt)(1−βt−1)xt−2+1−(1−βt)(1−βt−1)ϵ(3)
令αt=1−βt,αtˉ=∏i=1tαi,我们最终可以得到通项公式
xt=αtˉx0+1−αtˉϵ(4)